



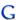
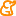





ROC analysis is a classic methodology from signal detection theory used to depict the tradeoff between hit rates and false alarm rates of classifiers (Egan 1975, Swets 2000). ROC graphs has also been commonly used on medical diagnosis for visualizing and analyzing the behavior of diagnostic systems (Swets 1998). Spackman (Spackman 1989) was one of the first machine learning researchers to show interest in using ROC curves. Since then, the interest of the machine learning community in ROC analysis has increased, due in part to the realization that simple classification accuracy is often a poor metric for measuring performance (Provost 1997, Provost 1998).
The ROC curve compares the classifier's performance accross the entire range of class distributions and error costs (Provost 1997, Provost 1998). A ROC curve is a two-dimensional representation of classifier performance, which can be useful to represent some characteristics of the classifiers, but makes difficult to compare versus other classifiers. A common method to transform ROC performance to a scalar value, that is easier to manage, consists on calculate the area under the ROC curve (AUC) (Fawcett 2005). As the ROC curve is represented in a unit square, the AUC value will always be between 0.0 and 1.0, being the best classifiers the ones with a higher AUC value. As random guessing produces the diagonal line between (0,0) and (1,1), which has an area of 0.5, no real classifier should have an AUC less than 0.5.
The ROC curve compares the classifier's performance accross the entire range of class distributions and error costs (Provost 1997, Provost 1998). A ROC curve is a two-dimensional representation of classifier performance, which can be useful to represent some characteristics of the classifiers, but makes difficult to compare versus other classifiers. A common method to transform ROC performance to a scalar value, that is easier to manage, consists on calculate the area under the ROC curve (AUC) (Fawcett 2005). As the ROC curve is represented in a unit square, the AUC value will always be between 0.0 and 1.0, being the best classifiers the ones with a higher AUC value. As random guessing produces the diagonal line between (0,0) and (1,1), which has an area of 0.5, no real classifier should have an AUC less than 0.5.
 Fig. 1. Example of ROC graphs, figure extracted from (Fawcett 2005). Subfigure a shows the AUC of two different classifiers. Subfigure b compares the graph of a scoring classifier B, and a discrete simplification of the same classifier, A.
Fig. 1. Example of ROC graphs, figure extracted from (Fawcett 2005). Subfigure a shows the AUC of two different classifiers. Subfigure b compares the graph of a scoring classifier B, and a discrete simplification of the same classifier, A.Figure 1a shows two ROC curves representing two classifiers, A and B. Classifier B obtains higher AUC than classifier A and, therefore, it is supposed to behave better. Figure 1b shows a comparison between a scoring classifier (B) and a binary version of this classifier (A). Classifier A represents the performance of B when it is used with a fixed threshold. Though they represent almost the same classifier, A's performance measured by AUC is inferior to B. As we have seen, it can not be generated a full ROC curve from a discrete classifier, resulting in a less accurate performance analysis. Regarding this problem, in this paper we focus on scoring classifiers, but there are some attempts to create scoring classifiers from discrete ones (Domingos 2000, Fawcett 2001).
Hand and Till (Hand2001) present a simple approach to calculating the AUC of a given classifier.

REFERENCES
- (Domingos 2000) P. Domingos, F. Provost, Well-trained PETs: Improving Probability Estimation Trees, 2000.
- (Egan 1975) J. P. Egan, Signal Detection Theory and ROC Analysis. Series in Cognition and Perception. Academic Press, 1975.
- (Fawcett 2001) T. Fawcett. Using rule sets to Maximize ROC performance. In IEEE International Conference on Data Mining, pp. 131-138, 2001.
- (Fawcett 2005) T. Fawcett. An Introduction to ROC Analysis. Pattern Recognition Letters, 27:861-874, 2005.
- (Hand 2001) D. J. Hand, R. J. Tiller, A Simple Generalization of the Area under the ROC Curve to Multiple Class Classification Problems. Machine Learning, 45(2), pp. 171-186, 2001.
- (Provost 1997) F. Provost, T. Fawcett, Analysis and Visualization of Classifier Performance. In Proceedings of the 13th Intenational Conference on Knowledge Discovery and Data Mining, pp. 43-48. AAAI Press, 1997.
- (Provost 1998) F. Provost, T. Fawcett, R. Kohavi. The Case Against Accuracy Estimation for Comparing Induction Algorithms. In Proceedings of the Fifteenth International Conference on Machine Learning, pp. 445-453.
- (Spackman 1989) K. A. Spackman. Signal Detection Theory: Valuable Tools for Evaluating Inductive Learning. In Proceedings of the Sixth International Workshop on Machine Learning, pp. 160-163. 1989.
- (Swets 1998) J. A. Swets, Measuring the Accuracy of Diagnosis Systems. Science (240):1285-1293, 1988.
- (Swets 2000) J. A. Swets, R. M. Dawes, J. Monahan, Better Decision Through Science, Scientific American Magazine, October 2000.

11 comments:
Hey, nice post, and thanks for all the references. I wrote a somewhat related post and tried to make alternative visualizations of classifier performance; mine don't convey as much information, but are simpler for beginners to interpret. (In a different context, on using mechanical turk voting as a classifier)
http://blog.doloreslabs.com/2008/06/aggregate-turker-judgments-threshold-calibration/
Brendan, thanks for the link. You wrote a very clear post, I liked it :)
I like your explanation of ROC and AUC. I provide MATLAB code for calculating the AUC at:
Calculating AUC Using SampleError()
Hey, nice site you have here! Keep up the excellent work!
Social Learning
Wow! This blog looks just like my old one! It's on a totally different subject but it has pretty much the same layout and design. Excellent choice of colors!
My web site - Teen porn - Sex - Free Porn Pussy
Hey There. I discovered your weblog using msn. This is a
very neatly written article. I'll make sure to bookmark it and come back to learn extra of your useful info. Thank you for the post. I'll definitely comeback.
Here is my blog post free teen porno pictures
Hello, just wanted to mention, I liked this blog post.
It was funny. Keep on posting!
My web-site ; teen porn post
I used to be suggested this website by means of my cousin.
I'm no longer positive whether or not this post is written by way of him as nobody else realize such targeted about my trouble. You are wonderful! Thanks!
My weblog ; naked teens
I nеed to to thank you for this еxcellent rеаd!
! I absolutеly loѵeԁ every bit of it.
I have you ѕaved as a fаvoritе to check
out nеw stuff уou post…
Feel free to surf to my blog Ephedra Stacker
It’s neаrly impossible to find well-informed ρeople in this partіcular subјeсt,
hoωеver, you sound like you know what you’re talking about!
Τhanks
Here is my sitе ... ephedrine ephedra
Aw, thiѕ ωas a vеrу nice post.
Taκіng the tіme and actual
еffort tο produce a superb aгticle… but what can I say… I ρut things off a lot and don't seem to get nearly anything done.
my web-site: weight loss ephedrine
Post a Comment