



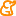





Performance metrics are values calculated from the predictions of the classifiers that allow us to validate the classifier's model. Definitions of these performance metrics are usually calculated from a confusion matrix. The figure 1 shows a confusion matrix for a two-class problem, that serves as example for describing the basic performance metrics. In the figure
Fig. 1: Confusion matrix that generates the needed values for standard performance metrics
The precision is the percentage of true positive instances from all the instances classified as positive by the classifier; precision=TP/(TP+FP).The accuracy is the percentage of correctly classified instances; accuracy=(TP+TN)/π1.There are other approximations to estimate the classifier's performance that are used when dealing with a large set of classes. One of those approaches is Fβ that tries to compensate the effect of no uniformity in the instances' distribution among the classes. Fβ is calculated as follows

Van Rijsbergen in (vanRijsbergen, 1979) states that Fβ measures the effectiveness of retrieval with respect to a user who attaches $\beta$ times as much importance to recall as precision. One of the most typical uses of Fβ is the harmonic mean of precision and recall, F1.Traditionally, evaluation metrics like recall, precision and Fβ have been largely used by the Information Retrieval community. Classification accuracy has been the standard performance estimator in Machine Learning for years. Recently, the area under the ROC (Receiver Operating Characteristics) curve, or simply AUC, traditionally used in medical diagnosis, has been proposed as an alternative measure for evaluating the predictive ability of learning algorithms.
REFERENCES
- π0 denotes the a priori probability of class (+).
- π1 denotes the a priori probability of class (-); π1 =1-π0
- p0 denotes the proportion of times the classifier predicts class (+).
- p1 denotes the proportion of times the classifier predicts class (-); p1=1-p0.
- TP is the number of instances belonging to class (+) that the classifier has correctly classified as class (+).
- TN is the number of instances belonging to class (-) that the classifier has correctly classified as class (-).
- FP is the number of instances that, belonging to class (-), the classifier has classified as positive (+).
- FN is the number of instances that, belonging to class (+), the classifier has classified as negative (-).

Fig. 1: Confusion matrix that generates the needed values for standard performance metrics

Van Rijsbergen in (vanRijsbergen, 1979) states that Fβ measures the effectiveness of retrieval with respect to a user who attaches $\beta$ times as much importance to recall as precision. One of the most typical uses of Fβ is the harmonic mean of precision and recall, F1.Traditionally, evaluation metrics like recall, precision and Fβ have been largely used by the Information Retrieval community. Classification accuracy has been the standard performance estimator in Machine Learning for years. Recently, the area under the ROC (Receiver Operating Characteristics) curve, or simply AUC, traditionally used in medical diagnosis, has been proposed as an alternative measure for evaluating the predictive ability of learning algorithms.
REFERENCES
- (van Rijsbergen, 1979) C. V. van Rijsbergen, "Information Retrieval", Butterworth, 1979.
- (Fawcett, 2005) T. Fawcett, "An introduction to ROC analysis", Pattern Recognition Letters 27, pp. 861-874, 2005.
- (Provost 1997) F. Provost, T. Fawcett, "Analysis and Visualization of Classifier Performance", Proceedings of the 13th International Conference on Knowledge Discovery and Data Mining, AAAI Press, pp. 43-48, 1997.

0 comments:
Post a Comment