There are two general Machine Learning articles that I think are very relevant to understand actual and possible future trends in Machine Learning:
[1] Dietterich, Thomas G., Machine Learning Research: Four Current Directions. The AI Magazine, Volume 18, pp 97-136. 1997.
[2] Domingos, Pedro, Machine Learning. In W. Klosgen and J. Zytkow (eds.), Handbook of Data Mining and Knowledge Discovery (pp. 660-670), 2002. New York: Oxford University Press.
Now we are on 2006, almost 10 years later than the publication date of the first article, but some of its reasonings are also valid today. But when thinking about actual and future trends in Machine Learning, I prefer to start from Pedro Domingo's point of view. Machine Learning has found in Data Mining (KDD) its business partner and it has been a crucial meeting just because KDD means more money for Machine Learning research and also means real applications (not only theoretical research).
¿And what is and can be useful from Machine Learning for KDD? First at all, the preprocessing step in KDD can be considered as (or even much) important than the knowledge discovery stage, and that's why new, effective and fast Feature Extraction, Construction and Selection ([3]) algorithms seem to be as important as new Classifiers or Clusters. From my point of view, there is a need for theoretical/practical papers comparing the performance and scalability of actual Feature Selection algorithms including filters, wrappers, embedded and even genetic based approach.
There are a lot of classifiers, clusters and regression algorithms and that's (with the good results with actual algorithms) why I think developing new algorithms is not a crucial task, but as [1] exposes, Emsemble Learning can be very useful as it studies how to combine existing algorithms to achieve better results. More useful, even, is study distribute multi agent ensemble of classifiers (as there are many intrinsic distributed problems).
[3] JMLR Special Issue on Variable and Feature Selection
Machine Learning: Two interesting trends
Distributed and Ubiquitous Data Mining Wiki
The DIADIC Research Lab at University of Maryland Baltimore County (UMBC) mantains the DDMWiki. As they say:
"This is a free Distributed and Ubiquitous Data Mining (DDM) encyclopedia that anyone can edit. This wiki is being developed to offer information about all aspects of Distributed and Ubiquitous Data Mining. Part of our aim is to ultimately extend this wiki into an online Distributed Data Mining community. Anyone, including you, can edit this wiki. You can add your publications, links, websites, conference CFPs, blogs etc. directly at the appropriate pages."
Machine Learning for Newbies
In [1] Pedro Domingos recopilates some Machine Learning related stuff that can be useful for a beginner in the field. There is a list of journals
- Machine Learning
- Journal of Artificial Intelligence Research
- Neural Computation
- IEEE Transactions on Pattern Analysis and Machine Intelligence
- Journal of Machine Learning Research
- Journal of Machine Learning Gossip
- International Conference on Machine Learning
- European Conference on Machine Learning
- International Joint Conference on Artificial Intelligence
- National Conference on Artificial Intelligence
- European Conference on Artificial Intelligence
- Annual Conference on Neural Information Processing Systems
- International Workshop on Multistrategy Learning
- International Workshop on Artificial Intelligence and Statistics
- International Conference on Computational Learning Theory (COLT)
- European Conference on Computational Learning Theory
- UCI repository of machine learning databases
- Online bibliographies of several subareas of machine learning
- Machine Learning List
- AI and Statistics List
- MLC++
- Weka
- Citeseer
- DBLP
- Rexa
- DataSets for Data Mining and Knowledge Discovery
- DataMining Conferences
- Machine Learning (Theory)
References:
[1] Pedro Domingos, "E4 - Machine Learning" In W. Klosgen and J. Zytkow (eds.), Handbook of Data Mining and Knowledge Discovery (pp. 660-670), 2002. New York: Oxford University Press. (Download)
Bias in Machine Learning
In statistics, the term bias is used in two different ways
- A biased sample is a statistical sample where their members have not the same probability to be chosen.
- A biased estimator is one estimator that over or understimates the quantity to be estimated.
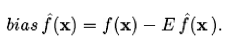 reflecting sensivity to the target function f(x). The bias represents "how closely on average the estimate is able to approximate the target". The bias has direct effects on the predicted error as we can decompose it as follows [2]
reflecting sensivity to the target function f(x). The bias represents "how closely on average the estimate is able to approximate the target". The bias has direct effects on the predicted error as we can decompose it as follows [2]
References
[1] J. H. Friedman, "On bias, variance, 0/1 loss, and the curse-of-dimensionality", Data Mining and Knowledge Discovery vol.1, nº 1, 55-77, 1997. (Download).
[2] G. M. James, "Variance and Bias for General Loss Functions", Machine Learning 51, nº 2, 115-135, 2003. (Download)
Mixture of Experts
Mixture of Experts is based on the "Divide and Conquer" doctrine. The problem is divided into manageable sizes for several experts and each expert learns locally from a part of the problem domain and then the outputs from these experts are combined to provide a global output.
Mixture of Experts are oriented to Neural Network, being each expert a neural network that learns only from a part of the problem and the outputs are combined by human knowledge or by gating networks. But Mixture of Experts seems to be an abstract paradigm and could be applied with other classifiers.
Basic References
[1] Jong-Hoon Oh and Kukjin Kang, "Experts or an Ensemble? A Statistical Mechanics Perspective of Multiple Neural Network Approaches" (Download)
[2] Jordan, M. I. "Hierarchical Mixtures of Experts and the EM algorithm" Neural Computation 6, 181-214, 1994 (Download)
Linear Transformation Methods
I'm interested on Linear Transformation Methods that allow us to transform an initial representation into another representation where the components are, in some way, independents. Our work with FBL (a Wrapper to improve Naive Bayes by deleting the dependent attributes) tries to do something similar and I would compare all those methods to FBL. The Linear Transformation Methods I've found are
- Principal Component Analysis
- Factor Analysis
- Projection Pursuit
- Independent Component Analysis
- Independent Factor Analysis
- Generalized Additive Models
Paper: "The Role of Occam's Razor in Knowledge Discovery"
Reference: “The Role of Occam's Razor in Knowledge Discovery.” Data Mining and Knowledge Discovery, 3, 409-425, 1999.
Download
I found this paper, by Pedro Domingos, very interesting. It analyzes the role developed by the Occam’s Razor in KDD and studies (referencing a lot of papers where Occam’s Razor is explicitly or implicitly applied) the correctness of applying it.
Pedro Domingo says the Occam’s Razor in KDD can be seen as
- “Given two models with the same generalization error, the simpler one should be preferred because simplicity is desirable in itself” or...
- ...“Given two models with the same training-set error, the simpler one should be preferred because it is likely to have lower generalization error.”
The second version of the Occam’s Razor is clearly mistaken, as a low training-set error usually derives into overfitting, and a high generalization error. Pedro Domingos gives some arguments to favor and against this second one, concluding that “the second version is provably and empirically false”. The first version seems right but uses simplicity as a proxy to comprehensibility, resulting in some quite different from Occam’s Razor.
Ensemble Learning (A very short introduction)
Ensemble methods are methods than rather than finding one best hypothesis for the learning problem construct a set of hypotheses (called "committee" or "ensemble") that can, in some fashion, "vote" to predict the class of the new data example. As defined in [1], "an ensemble method constructs a set of hypothesis {h1, . . . , hk}, chooses a set of weights {w1, . . . , wk} and constructs the "voted" classifier
The classification decision of the combined classifier is +1 if H(x) >= 0 y -1 otherwise"
Ensemble learning algorithms work running a base learning algorithm multiple times, generating a hypothesis at each iteration. The hypothesis can be generated in two ways
1) In a independent way, resulting in a set of diverse hypothesis. It can be done by running the algorithm several times and providing different training data at each iteration or providing different subsets of the input features at each iteration. An example of this way is Bagging [2].
2) In an additive way, adding one hypothesis at a time to the ensemble, and constructing the hypothesis trying to minimize the classification error on a weighted training data set. An example of this way is Boosting [3], [4].
Bagging (“Bootstrap Aggregatting”)
Given a training data with m examples, Bagging works by generating at each iteration a new training data set of m examples by sampling uniformly from the original examples, which means some original examples appear multiple times and other original examples do not appear in the resampling. If the learning algorithm is unstable (small changes in the training data causes large changes in the hypothesis, like decision trees) then Bagging will produce a set of diverse hypothesis (H).
Having H, for classifying a new example, we should proceed to a voting between all the hypothesis hi belonging to H, and the final classification would be the most voted one.
Boosting
Boosting assings a weight to each training sample and then, at each iteration, generates a model that tries to minimize the sum of the weights of the misclassificated examples. The errors at each iteration are used to actualize the weights of the training samples, increasing the misclasificated instances’ weights and decreasing the correctly classificated instances’ weights.
¿Why use Ensembles?
[5] gives a good justification of ensemble using.

- "The first cause of the nees for ensembles is that the trainning data may not provide sufficient information for choosing a single best classifier from H. Most of our learning algorithms consider very large hypothesis spaces, so even after eliminating hypotheses that misclassify training examples, there are many hypothesis remaining".
- "A second cause...is that our learning algorithms may not be able to solve the difficult search problems that we pose"
- "A third cause...is that our hypothesis space H may not contain the trus function f"
Basic References
[1] Dietterich, T. G. (2002). "Ensemble Learning." In The Handbook of Brain Theory and Neural Networks, Second edition, (M.A. Arbib, Ed.), Cambridge, MA: The MIT Press, 2002. 405-408. (Download)
Specific References
[2] Breiman, L. (1996a), "Bagging Predictors", Machine Learning, Vol. 24, No. 2, pp. 123-140. (Download)
[3] Yoav Freund and Robert E. Schapire. "Experiments with a new boosting algorithm." In Machine Learning: Proceedings of the Thirteenth International Conference, pages 148-156, 1996. (Download)
[4] J. R. Quinlan, "Bagging, Boosting, and C4.5 (1996)", AAAI/IAAI, Vol. 1 (Download)
Other References:
[5] Dietterich, T. G, "Machine Learning: Four Current Directions" (1997) (Download)
Ensemble Learning Researchers:
A reading list on Bayesian methods
Tom Griffiths mantains a list of papers related to Bayesian methods. It seems a good place for starting Bayesian researchers:
http://www.cog.brown.edu/~gruffydd/bayes.html
Bayesian Model Averaging (A very simple description)
When trying to select a model that explains the data, we usually select (from all the possible models) the one which better fits the data. But sometimes we have some model that explains really well the data, creating a model selection uncertainty, which is usually ignored. BMA (Bayesian Model Averaging provides a coherent mechanism for accounting for this model uncertainty, combining predictions from the different models according to their probability.
As an example, consider that we have an evidence D and 3 possible hypothesis h1, h2 and h3. The posterior probabilities for those hypothesis are P( h1 | D ) = 0.4, P( h2 | D ) = 0.3 and P( h3 | D ) = 0.3. Giving a new observation, h1 classifies it as true and h2 and h3 classify it as false, then the result of the global classifier (BMA) would be calculated as follows:
Basic BMA Bibliography
[1] J. A.and Madigan D. Hoeting and A.E.and Volinsky C.T. Raftery. Bayesian model averaging: A tutorial (With Discussion). Statistical Science, 44(4):382--417, 1999. (Download)
Basic BMA Researchers

Composite Methods for Machine Learning
The Occam's razor is present everywhere, even in Machine Learning, where when some models fit the training data we usually select the simplest one as the model we are going to use. As said in [1] the Greek philosopher Epicurus defended a thesis far away from Occam's Razor, he defended that if two or more hypothesis fit the data, we should use all of them, not only one of them. Composite methods are machine learning techniques/algorithms where we use more than one model/hypothesis/classifier to obtain a better result in our machine learning task. Inside Composite Methods there are very different methods, resumed in the next more or less general techniques:
1.- Bayesian Model Averaging
2.- Ensemble Methods
2.1.- Bagging
2.2.- Boosting
2.3.- Other Fussion Methods
3.- Mixture of Experts
3.1.- Gating Networks
4.- Local Learning Algorithms
4.1.- RBF
4.2.- KNN
5.- Hybrid Methods
5.1.- Cascade
5.2.- Stacking
6.- Composite Methods for Scaling or Distributing ML algorithms
I'm going to spend some post describing, in a general way, all this techniques.
[1] "Introducción a la Minería de Datos" José Hernández Orallo, M.José Ramírez Quintana, Cèsar Ferri Ramírez, Pearson, 2004. ISBN: 84 205 4091 9
"Introducción a la Minería de Datos"
Authors: José Hernández Orallo, M.José Ramírez Quintana, Cèsar Ferri Ramírez
Editorial: Pearson 2004.
ISBN: 84 205 4091 9
Web: http://www.dsic.upv.es/~flip/LibroMD
This book is really a brilliant spanish introduction to the Data Mining World. It covers from basic topics (in the two first parts of the book) as What is Data Mining? (¿Qué es la minería de datos?), the stages in the datamining process, datawarehousing, cleaning and transformation, attributes and instances selection, then, in part III explains the most important Data Mining techniques (association rules, bayesian methods, decision tress, rule based systems, etc.). In part IV and V explains some more complex topics in datamining as are evaluation methods, combination of models, text mining, etc. and finally concludes with the implantation and impact of datamining systems.
I think it is a should read book for any Spanish speaker that wants to know about datamining and machine learning related topics, but taking care that this is an INTRODUCTION book, that explains everything from a very educative perspective.
Colaborators:
Tomàs Aluja Banet (Universitat Politècnica de Catalunya)
Xavier Carreras Pérez (Universitat Politècnica de Catalunya)
Emilio S. Corchado Rodríguez (Universidad de Burgos)
Mª José del Jesus Díaz (Universidad de Jaén)
Pedro Delicado Useros (Universitat Politècnica de Catalunya)
Vicent Estruch Gregori (Universitat Politècnica de València)
Colin Fyfe (University of Paisley, Reino Unido)
José Antonio Gámez Martín (Universidad de Castilla-La Mancha)
Ismael García Varea (Universidad de Castilla-La Mancha)
Pedro González García (Universidad de Jaén)
Francisco Herrera Triguero (Universidad de Granada)
Pedro Isasi Viñuela (Universidad Carlos III de Madrid)
Lluís Màrquez Villodre (Universitat Politècnica de Catalunya)
José Miguel Puerta Callejón (Universidad de Castilla-La Mancha)
Enrique Romero Merino (Universitat Politècnica de Catalunya)

Data Mining
Definition extracted from "Information Visualization In Data Mining And Knowledge Discovery", Usama Fayyad, Georges G. Grrinstein & Andreas Wierse:
"Data mining: Mechanized process of identifying or discovering useful structure in data"
