








When trying to select a model that explains the data, we usually select (from all the possible models) the one which better fits the data. But sometimes we have some model that explains really well the data, creating a model selection uncertainty, which is usually ignored. BMA (Bayesian Model Averaging provides a coherent mechanism for accounting for this model uncertainty, combining predictions from the different models according to their probability.
As an example, consider that we have an evidence D and 3 possible hypothesis h1, h2 and h3. The posterior probabilities for those hypothesis are P( h1 | D ) = 0.4, P( h2 | D ) = 0.3 and P( h3 | D ) = 0.3. Giving a new observation, h1 classifies it as true and h2 and h3 classify it as false, then the result of the global classifier (BMA) would be calculated as follows: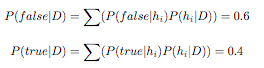
Basic BMA Bibliography
[1] J. A.and Madigan D. Hoeting and A.E.and Volinsky C.T. Raftery. Bayesian model averaging: A tutorial (With Discussion). Statistical Science, 44(4):382--417, 1999. (Download)
Basic BMA Researchers
Bayesian Model Averaging (A very simple description)
.
Thursday, April 20, 2006

1 comments:
This was lovelyy to read
Post a Comment